Consistent hashing is a way of hashing that ensures that adding or removing a slot or node does not change the mapping of keys to slots significantly. When using consistent hashing, only K/n keys need to be remapped on average - where K is the number of keys and n is the number of slots.
The way this works is that both keys and slots are mapped to edges of a circle. Meaning that all slots are mapped on to a series of angles around a circle. And the bucket where each item should be stored is chosen by selecting the next highest angle which an available bucket maps to. So, each bucket contains resources mapping to an angle between it and the next smallest angle. If a bucket becomes unavailable, the keys being mapped to that bucket get mapped to the next highest bucket (or the next bucket in the circle). So, only keys which were in the bucket which became unavailable is lost. Similarly when a bucket is added, the keys between the new bucket and the next smallest bucket is mapped to the new bucket. Keys which should be associated with the new bucket and were stored previously will become unavailable.
 |
| figure 2 |
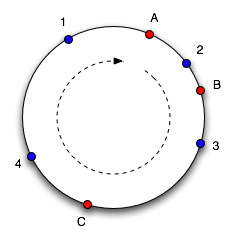 |
| figure 1 |
Here is an example. Objects 1,2,3 and 4 map to slots A,B and C. To find which slot an object goes in, we move around the circle until we find a slot. So here objects 1 and 4 go into slot A, 2 goes into slot B and 3 goes into slot C. If C is removed, object 3 would belong to slot A. If another slot D is added as shown in figure 2, it will take objects 3 and 4 and only leave object 1 belonging to A.
Lets look at a php example which does consistent hasing us.
<?php
class ConsistentHasher
{
private $nodeDistribution;
private $virtualNodes;
// nodeDistribution is the replica count per node.
public function __construct($nodenames, $nodedistribution)
{
$this->nodeDistribution = $nodedistribution;
$this->virtualNodes = array();
for($i=0; $i<count($nodenames); $i++)
{
$this->addNode($nodenames[$i]);
}
}
// The addNode() function takes a name and creates virtual nodes (or replicas) by
// appending the index of the local loop to the node name.
// The hash value of a virtual node is an MD5 hash, base converted into an integer.
// The virtual node is added to a list and sorted by its value so that we ensure
// a lowest to highest traversal order for looking up previous and next virtual nodes
public function addNode($name)
{
for($i=0; $i<$this->nodeDistribution; $i++)
{
//int representation of $key (8 hex chars = 4 bytes = 32 bit)
$virtualNodeHashCode = base_convert(substr(md5($name.$i, false),0,8),16,10);
$this->virtualNodes[$name.$i] = $virtualNodeHashCode;
}
asort($this->virtualNodes, SORT_NUMERIC);
}
public function dump()
{
print_r($this->virtualNodes);
echo "\n\n";
}
public function sortCompare($a, $b)
{
if($a == $b)
{
return 0;
}
return ($a < $b) ? -1 : 1;
}
// The removeNode() function takes a name and removes its corresponding virtual nodes
// from the virtualNode list.
// We then resort the list to ensure a lowest to highest traversal order.
public function removeNode($name)
{
for($i=0; $i<$this->nodeDistribution; $i++)
{
unset($this->virtualNodes[$name.$i]);
}
asort($this->virtualNodes, SORT_NUMERIC);
}
// The hashToNode() function takes a key and locates the node where its value resides.
// We loop through our virtual nodes, stopping before the first one that has a
// hash greater than that of the key’s hash.
// If we come to the end of the virtual node list, we loop back to the beginning to
// form the conceptual circle.
public function hashToNode($key)
{
$keyHashCode = base_convert(substr(md5($key, false),0,8),16,10);
$virtualNodeNames = array_keys($this->virtualNodes);
$firstNodeName = $virtualNodeNames[0];
$lastNodeName = $virtualNodeNames[count($virtualNodeNames)-1];
$prevNodeName = $lastNodeName;
foreach($this->virtualNodes as $name => $hashCode)
{
if($keyHashCode < $hashCode)
return $prevNodeName;
if($name == $lastNodeName)
return $firstNodeName;
$prevNodeName = $name;
}
return $prevNodeName;
}
}
// demo
$hash = new ConsistentHasher(array("node1","node2","node3","node4","node5"),10);
$hash->dump();
$hash->removeNode("node2");
$hash->dump();
$hash->addNode("node6");
$hash->dump();
echo $hash->hashToNode("testing123")."\n";
echo $hash->hashToNode("key1111")."\n";
echo $hash->hashToNode("data4444")."\n";
?>
Here is a library which provides consistent hasing for php
http://code.google.com/p/flexihash/
Memcache is a widely used distributed cache which uses consistent hashing very efficiently to map keys to caching nodes.
References:
http://en.wikipedia.org/wiki/Consistent_hashing
http://www.osconvo.com/post/view/2010/9/1/distributed-hashing-algorithms-by-example-consistent-hashing
